The Simplest True Thing About AI Agents
Strip away LangGraph, CrewAI, the OpenAI Agents SDK, and every other framework competing for your attention right now. What’s left? A while loop.
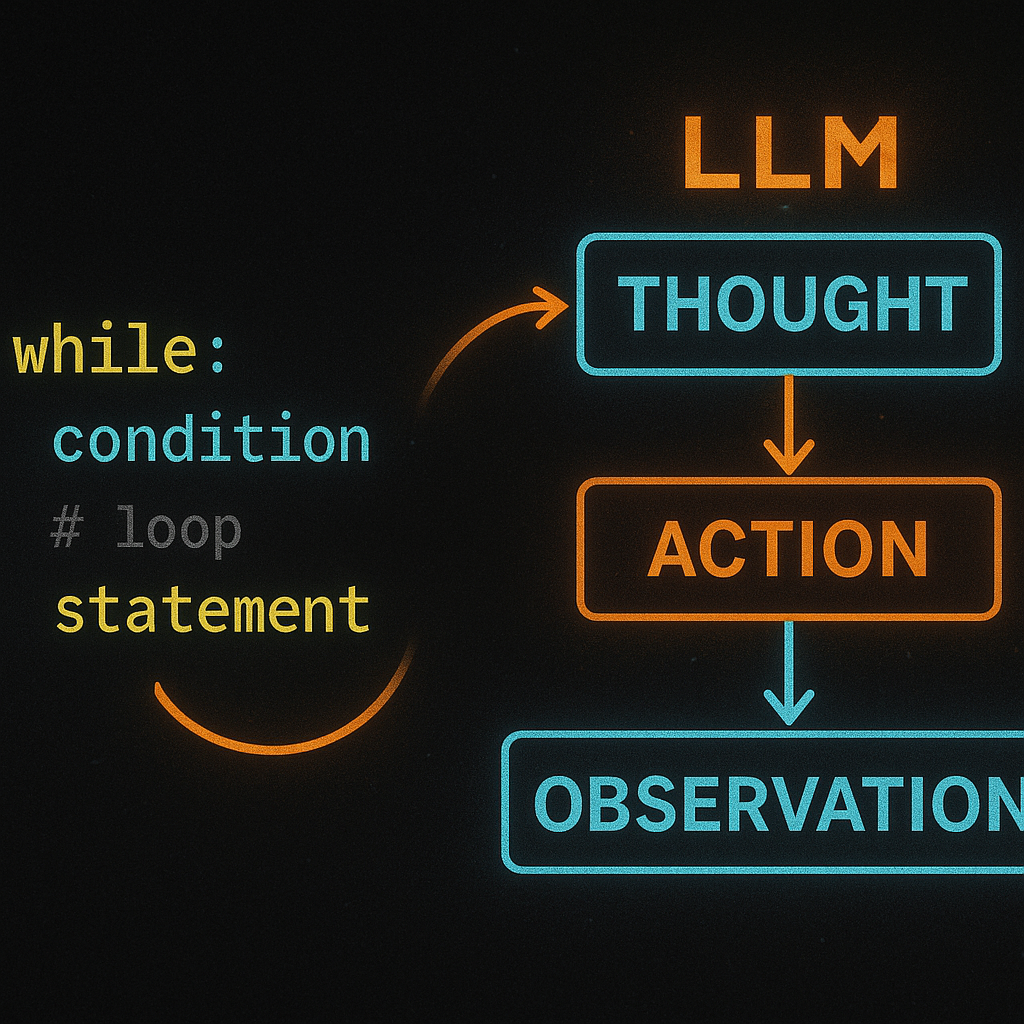
The LLM calls a tool. It sees the result. It decides what to do next. It repeats until it has an answer. That is the complete picture. Steve Kinney put it plainly: “A while loop that calls an LLM, checks if the response contains tool calls, executes them if it does, and stops if it doesn’t. That’s the whole thing.” Every major framework converges on this. Not similar logic. The same logic, wrapped in progressively more sophisticated scaffolding.
Boris Cherny, Head of Claude Code at Anthropic, described the shift at WorkOS Acquired Unplugged in June 2026: “I don’t prompt Claude anymore. I have loops that are running. They’re the ones who are prompting Claude and figuring out what to do. My job is to write loops.”
The Difference Between a Workflow and an Agent
This distinction matters before going further. A workflow is a predetermined sequence where you, the developer, define the control flow. An agent is an open-ended loop in which the model determines the control flow. The while loop is the minimum viable agent because it hands the steering wheel to the LLM. Memory, planning, and retrieval-augmented generation are all add-ons. The loop is the thing.
The pattern at every step is the same: observe the context, decide on an action, execute, update the state, repeat.
The ReAct Pattern: Where the Loop Gets Structure
Raw loops work. But the most common structured approach is ReAct, introduced by Yao et al. In 2022. ReAct organizes each turn of the loop as three phases: a thought, an action (tool call), and an observation (the tool result). The model reasons over the observation before deciding the next action.
ReAct improves on static Chain-of-Thought by making the reasoning dynamic. Instead of generating a reasoning chain in one shot, the model updates its reasoning based on real environmental feedback at each step. Most modern frameworks, including LangGraph, the Vercel AI SDK, and the OpenAI Agents SDK, implement some variant of this pattern.
If you want a mental model outside of ML, the ReAct loop is a direct implementation of existing decision cycles like OODA (Observe-Orient-Decide-Act) or PDCA (Plan-Do-Check-Act). The concept is not new. Applying it to LLMs is.
A full working ReAct agent can be built in roughly sixty lines of Python. You give the LLM a list of tools with descriptions. You parse whether the response contains a tool call. If it does, you execute the tool and append the result to the conversation. If it does not, you stop and return the answer. The tool_choice parameter does the heavy lifting: auto lets the LLM decide whether to call a tool or return text (this is what makes it an agent), required forces a tool call on the first turn, and none prevents tool calls when you need to force a final answer.
What the Frameworks Are Actually Doing
Once you have the core pattern, the framework landscape becomes much easier to read. Every framework is solving a real problem that raw loops expose.
LangGraph adds a graph-based state machine so you can model branching, cycles, and checkpointing. It leads enterprise adoption with 34.5 million monthly PyPI downloads and around 400 production deployments, including Klarna, LinkedIn, Uber, and JPMorgan.
OpenAI Agents SDK, released in March 2025, makes handoffs a first-class primitive. An agent can explicitly transfer control to another agent, carrying conversation context through the transition. Each agent is defined with instructions, a model reference, tools, and a list of agents it can hand off to.
Google ADK, released in April 2025, uses a hierarchical agent tree where a root agent delegates to sub-agents. It natively supports the A2A (Agent-to-Agent) protocol, enabling communication between agents from different frameworks, and integrates tightly with Vertex AI and Gemini models.
CrewAI is the fastest path from idea to a working multi-agent prototype. PydanticAI adds type safety and built-in usage limits, which matters if cost control is a first-class requirement. For learning or simple single-agent tasks, plain Python with no framework overhead is still a legitimate choice.
Following the Model Context Protocol (MCP), released by Anthropic in November 2024, tools are standardized interfaces that allow agents to interact with local files, databases, and web APIs. With modern function-calling APIs, the LLM returns structured JSON directly, making custom output parsing largely unnecessary compared to earlier approaches.
Where Loops Break in Production
The honest part: most agent failures trace back to something going wrong inside the loop, not the model.
Infinite loops are the most common. An agent repeats the same reasoning step or tool call without making meaningful progress. The symptom is rising token cost, long runtime, and no state change in traces. A concrete example: an agent scraping a website finds the target has changed its structure, the tool returns empty, and without a hard stop, the agent retries the broken tool 400 times in five minutes before hitting a platform rate limit. A maximum iteration limit of three cycles prevents this entirely.
Context overflow is slower and harder to spot. A long-running loop accumulates every tool output, every intermediate thought, and every message, then stuffs all of it back into the context window on each turn. Eventually the window fills and calls either truncate silently or fail outright. The fix is context summarization at fixed intervals. Every N steps, compress accumulated history into a running summary so the working context stays bounded.
No-progress loops are a subtler variant of the infinite loop. The agent produces different outputs each turn, so naive iteration counting does not catch it. You need loop fingerprinting and no-progress detection to exit when repeated iterations produce no new information.
Every production loop needs all three guardrails: maximum iteration limits, no-progress detection, and a token/cost budget as a hard ceiling. The natural stop comes from the LLM’s decision. The safety stop comes from your code. Both are always required.
Picking Your Level of Abstraction
The three dominant paths for running agent loops in mid-2026 are: provider-managed runtimes (Anthropic’s Claude agents API and the OpenAI Agents SDK with hosted tools), LangGraph with LangSmith deployment for teams that need stateful, observable, production-grade pipelines, and plain API calls in a loop you own completely.
The right choice depends on what you are building and how much of the loop you need to see and control. If you are learning, start with sixty lines of Python. You will understand every framework decision that comes after because you will know exactly what problem each one is solving.
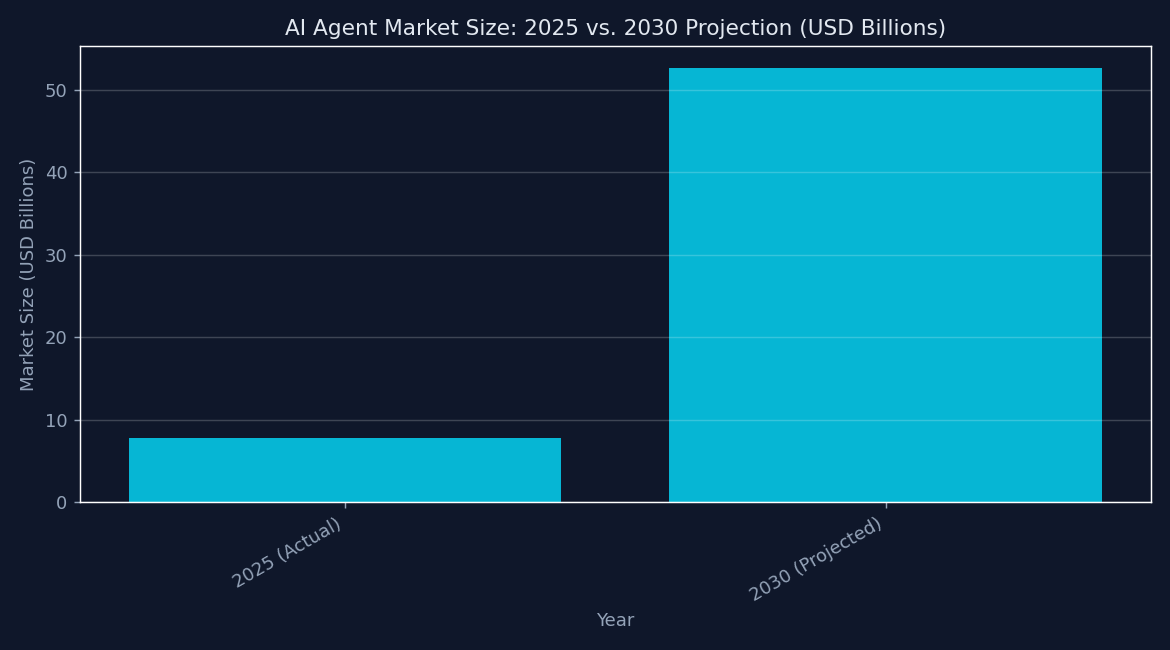
According to Markets and Markets, the global agent market reached $7.84 billion in 2025 and is projected to hit $52.62 billion by 2030 at a CAGR of 46.3%. Gartner predicts 40% of enterprise applications will feature task-specific AI agents by the end of 2026, up from less than 5% in 2025. The directional signal is clear. Agent loops are moving from experiments to infrastructure.
As one DEV Community contributor noted: “There’s a certain poetry to it. The most advanced AI technology we have, operating on the most fundamental programming construct.” A while loop. That really is all it is.